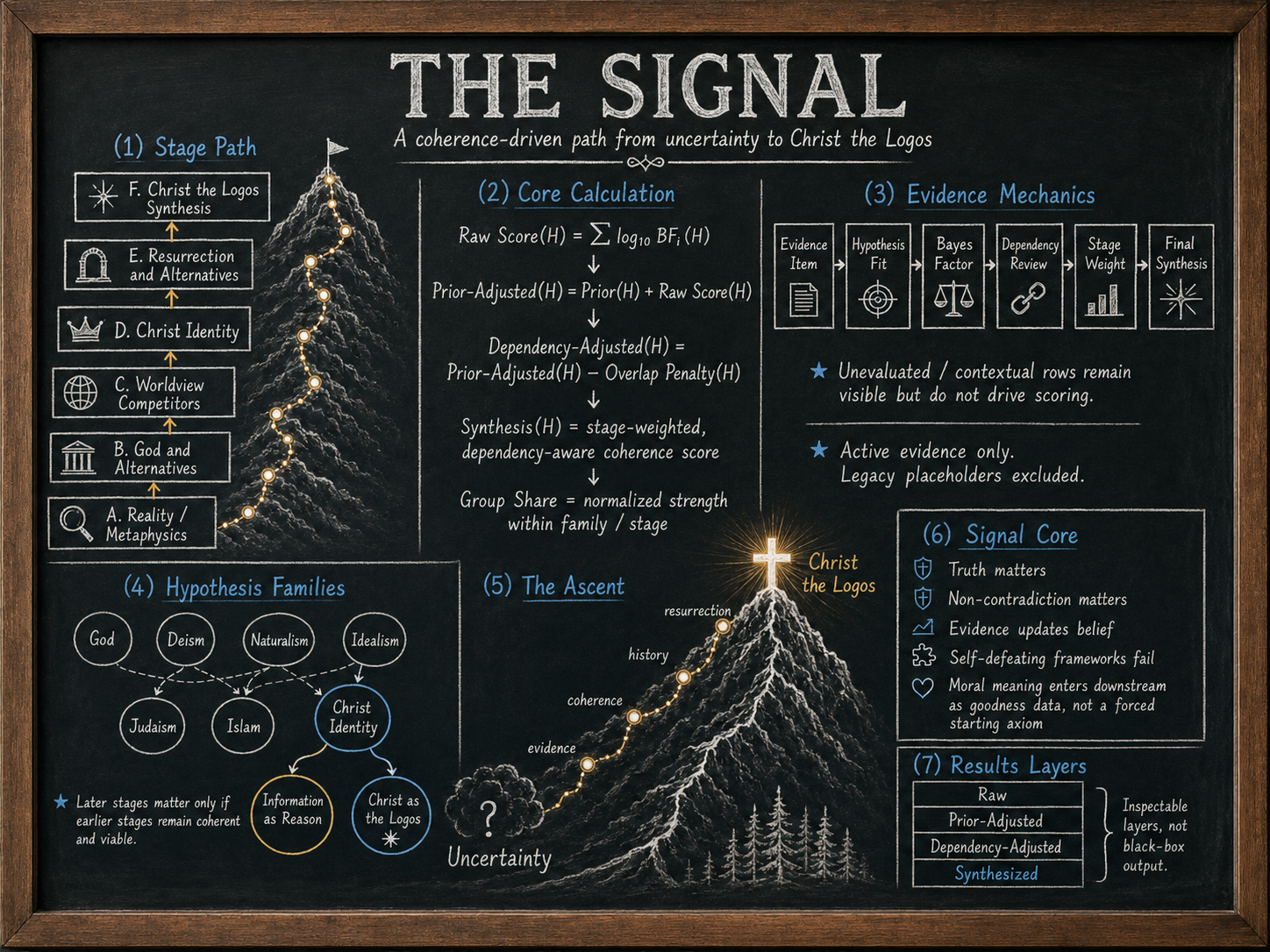
It evaluates hypothesis fit, applies Bayes factors, reads them through stated priors, controls overlap, and keeps raw totals, audit lenses, guided paths, and diagnostics in their proper categories.
Open imageMethod first: the result is not one isolated number. It is a layered calculation with visible assumptions and audit categories.
Rows stay bounded
Each evidence item asks how one datum fits live hypotheses. It does not become a free-floating proof.
Overlap is capped
Related rows are dependency-adjusted so a cluster cannot behave like many independent witnesses.
Outputs stay named
Strict audit, guardrail stress-test, guided staged path, sensitivity, and full diagnostic are different result categories.
The pipeline
The Signal begins with evidence items. Each item asks whether a bounded datum is more expected under one live explanation than another. That fit is expressed as a row-level log10 Bayes factor, then read through stated priors and dependency controls.
Evidence item: a bounded datum enters the map.
Hypothesis fit: the row asks which live explanations would expect the datum.
Bayes factor: active evidence gives directional weight using log10BF.
Prior adjustment: row pressure is read through stated prior profiles.
Dependency adjustment: overlap control reduces double counting.
Stage synthesis: earlier stages condition later questions under named rules.
Named result lens: the output is reported as strict audit, guardrail, guided path, sensitivity, or diagnostic.
The point is not to make the number smaller or larger. The point is to keep every constraint in its proper category.
Conceptual math
The public page does not require a reader to become a statistician. But the categories matter, because confusing them is one of the fastest ways to misread The Signal.
Layer
Plain meaning
Raw(H)
Sum of active log10 Bayes factors for hypothesis H before prior and overlap controls.
Posterior-style beta score(H)
Raw evidence interpreted through stated priors. These are inspection scores, not final worldview posteriors.
Dependency-adjusted(H)
Prior-adjusted score after related rows are shrunk so support families do not stack freely.
Conditioned prior(stage)
Later-stage starting point after governed upstream stage signal is carried forward.
Synthesis(H)
Stage-aware, dependency-aware coherence result under the named lens being reported.
Individual hypothesis values are posterior-style beta inspection scores. Raw totals, dependency-adjusted totals, strict audit calculation, guardrail ceiling stress-tests, guided staged-path outputs, browser-local scenarios, and full-strength diagnostics are different categories.
Where the Bayes factors come from
The active Bayes factors come from the canonical evidence files in data/evidence/items/*.json. For each scored row, the value used by the Results Engine is the row's bayes_factors[HYPOTHESIS_ID].log10BF.
Those canonical rows are rebuilt into the public mirrors data/evidence/evidence.jsonl and data/evidence/evidence.json. The mirrors are generated outputs; the actual item sources live under data/evidence/items/.
The strict audit, guardrail, guided staged-path, sensitivity, and full diagnostic outputs are calculated by tools/build_results_summary.py and written to data/runtime/results_summary.json. The synthesis model is described in data/runtime/synthesis_model.json.
Scored rows carry active log10BF values for one or more hypotheses.
Unweighted or contextual rows remain visible for interpretation, but do not drive synthesis.
Support-layer rows can matter, but should normally be modest and dependency-capped.
Defeater rows apply real counter-pressure. The Signal does not hide them.
Parent summaries explain clusters and list children, but stay unweighted unless an explicit parent-as-replacement run is approved.
Child rows remain inspectable and carry the active evidential weight when the parent is only a synthesis/context row.
This lets the reader see the structure while preventing the same evidence from being counted twice.
Dependency caps
Dependency adjustment is the anti-pileup layer. It prevents related evidence rows from behaving like wholly independent rows when they share sources, claims, clusters, or explanatory force.
The engine uses explicit governance metadata, including canonical_parent, canonical_anchor, dependency_cluster_id, dependency_cluster_role, dependency_weight_class, cap_family, cap_eligible, and metadata.cap_profile.
Cap profile
Current weight pattern
Used for
exact_duplicate
100%, then 0%, then 0%
Rows that restate the same governing datum.
support_layer_small
100%, then 35%, then 15%
Archaeology, manuscript texture, synchronisms, and support-layer rows that should stay small.
moderate_semi_independent
100%, then 50%, then 25%
Related but partly distinct evidence lanes such as high Christology, reason, mind, origin-of-life, or prophecy subfamilies.
rival_pressure
100%, then 50%, then 25%
Defeaters and rival-worldview pressure. Related objections do not stack as unrelated disproofs.
mixed_net_family
Positive and negative sides ranked separately
Families where support and counter-pressure live together, so unlike rows do not accidentally flip the sign.
Those profile weights are still constrained by dependency roles and weight classes. Parent/context rows count at 0%. A second row marked same_explanatory_family, sibling_support, shared_source, or support_layer is capped at 25%. A second row marked same_source, technical_child, context_child, or minor_support is capped at 15%. A second row marked semi_independent may count up to 50%.
Stage conditioning
Stage conditioning keeps later questions from being judged in a vacuum. A resurrection claim is not evaluated the same way under flat naturalism as it is after God and Christ identity have become live in earlier stages.
Earlier stages can raise or lower the starting point for later stages, but only under named transfer rules and named guardrails. Direct evidence is still applied after the conditioned starting point. Conditioning does not prove the later claim by itself.
Root reality and God/context evidence condition Christ identity.
Root context plus Christ-identity pressure condition Resurrection.
The final Logos audit combines root context, Christ identity, Resurrection, support layers, theology proper, direct Logos evidence, and comparator pressure.
If an auditor rejects a later result, the fair audit names which upstream stage is rejected, weakened, discounted, or recomputed.
This matters because a downstream Christian claim should not be reset to the original base prior as if the previous stages never happened. But neither should upstream evidence be allowed to settle the downstream question by itself.
Why cap conditioned priors?
Prior caps are guardrails against runaway confidence. If earlier stages make a later claim more plausible, the model is allowed to raise that later claim's starting point, but only up to a stated ceiling before direct evidence is considered.
In StrictAuditCalculation, the main hostile/fair audit keeps skeptical priors, rival pressure, dependency caps, and source limitations without adding an arbitrary global confidence ceiling. In AuditGuardrail75CeilingStressTest, the older 75% audit ceiling remains visible as a conservative stress-test. In GuidedStagedPathV1, carried priors use governed transfer weights without the old final 90% ceiling.
The point is not to say "this is already proven." The point is to say, "given the earlier stages, this later question is now live and strongly conditioned, but it still needs its own evidence."
Current named outputs
When summarizing The Signal's numerical outputs, report the named outputs separately. Do not collapse them into one number.
Output
Current v0.74 value
What it is
What it is not
Strict Audit Calculation
69.250948%
Main hostile/fair audit lens: skeptical priors, rival-positive pressure, dependency caps, source limitations, and no arbitrary global confidence ceiling.
Not a worldview-free neutral result, not proof, not salvation, and not the whole walked path.
Audit Guardrail: 75% Ceiling Stress-Test
65.767567%
Conservative global-ceiling stress-test retained visibly for transparency.
Not the headline fair audit posterior.
Guided Staged Path
96.474732%
The intended staged calculation: dependency-capped, transfer-weighted, rival-aware, and without a final confidence ceiling.
Not the old 90% carry-cap sensitivity and not generic unconditional certainty.
Guided 90% Carry-Cap Sensitivity
91.339078%
Older guided cap retained for audit comparison.
Not the main Guided Staged Path.
Full Signal Diagnostic
99.998045%
Full-strength upper-bound stress view under stated assumptions.
Not the strict audit result, not the 75% guardrail stress-test, not proof, certainty, salvation, or final unconditional posterior.
The separate browser-local FullSignalPathV1 asks where the reader starts and how much force each stage's evidence carries for them. Accepting the AI-assisted fairness weight at every stage is a strong concession: it means the reader is granting the staged evidence rather than merely inspecting it from outside.
First, the engine totals active log10BF values for each hypothesis. Then dependency adjustment shrinks overlap according to dependency metadata and cap profiles. Then audit and guided-path lenses use those adjusted signals in their named ways.
The audit calculation is stage-conditioned, dependency-adjusted, component-weighted, rival-aware, and source-limited. The guided staged path carries governed stage evidence forward with explicit transfer weights, dependency caps, and rival pressure. The full diagnostic asks what the staged model shows if the package's full cumulative force is accepted into Stage 5.
A compact expression of the final Logos audit is:
Final Logos = base odds + root component + Christ identity component + Resurrection component + support layers + theology proper + direct Logos evidence - strict monotheism pressure
That sentence should not be read as a magic formula. It is a map of the components. Each component remains governed by priors, dependency adjustment, transfer weights, and caveats.
What is fixed, what can move
The published Results Engine uses the stated evidence rows, active Bayes factors, hypothesis fits, stage flow, dependency groups, stage weights, and ConservativeFair prior profile. Reader controls in the app do not rewrite those public files.
Raw totals show active evidence before priors and overlap control.
Posterior-style beta scores show evidence read through the stated prior profile; they are not final posteriors.
Dependency-adjusted scores reduce double counting when related evidence rows travel together.
Guardrail ceilings and hostile caps are stress-test categories unless separately justified as the main calculation.
Stage synthesis keeps later claims in their proper sequence instead of flattening every hypothesis into one leaderboard.
Contextual or unweighted rows stay visible for interpretation, but they do not drive the beta synthesis.
Who set the weights?
The weights came from a long-running, multi-model, AI-assisted review process under human governance. AI systems helped draft, compare, criticize, stress-test, and propose bounded weights. The project owner governed the process, challenged weak moves, preserved rivals and caveats, corrected the map, and published the artifact.
The claim is not that AI independently proved Christianity. The narrower claim is that the numerical layer is an inspectable public discipline laid over the evidence. The weights are provisional, auditable, challengeable, and open to correction.
Some red rows may become green on deeper inspection; some green rows may need correction; some support rows should remain unweighted. That is why the row, rationale, caveat, source trail, and dependency family remain visible.
A valid audit names the category first, then the exact rows or clusters, the dependency assumptions, the replacement BF or cap proposal, and whether the result is official or diagnostic.
Name the result lens being challenged.
Name the exact evidence row IDs or dependency cluster IDs.
State whether the issue is a BF, prior, cap profile, source role, caveat, stage-transfer rule, or result-label problem.
Give the replacement value or dependency assumption.
Say whether the change is proposed for official runtime math or only for a diagnostic sensitivity run.
Without named rows, named clusters, and named recalculation mode, the honest verdict is: unclear pending named row or cluster audit.
Lower is not automatically fairer. Higher is not automatically inflated. Fairness means each constraint must correspond to a real uncertainty, dependency, source limitation, or rival pressure.
Common questions
Does The Signal prove Christianity with math?
No. The Signal uses structured quantitative language to expose reasoning under uncertainty. It does not replace Scripture, repentance, faith, the Church, or Christ Himself.
Why not just use the lowest number?
Because a lower result is not automatically fairer. A constraint is fair when it corresponds to a real dependency, source limitation, rival pressure, or uncertainty.
Why are there several result lenses?
Because strict audit, guardrail stress-test, guided staged path, old carry-cap sensitivity, full diagnostic, and browser-local reader scenario are different categories. Collapsing them into one number misrepresents the model.
Where should an auditor begin?
Begin with the evidence row, hypothesis, BF, citation trail, dependency cluster, cap profile, and result lens. A serious objection names the part of the map it wants changed.